Introduction
Back in the day, at TomTom, we had one developer who knew how to write the C++ code to encode maps to the SD card. We had another developer who knew how to write the C++ code to decode maps from the SD card. There was also a document that covered the map file format. All three were out of sync. The developers couldn’t read each other’s code, and the documentation never covered what was really going on.
So, when we were asked to reuse the map files for server-side rendering, we realized that it would worsen the problem exponentially. Now, we would have four different things that we would have to keep in sync.
This is when we started wondering if there would be a way to describe the mapping between an in-memory-based object representation and its compressed representation in a declarative way, and get the encoder, the decoder, and the documentation for free.
Previous Art
There have been some attempts to achieve this, but these attempts aimed to solve a problem in a particular domain (flavor, bflavor) with a limited set of compression techniques. In our case, there was no obvious limit to the types of compression that we would ever put in. So whatever the solution would be, it would have to accommodate an infinite number of compression techniques.
Preon: Codecs of Codecs
I realized that you can always construct a codec for any compressed data format by composing it out of other codecs. If, at some point, we come up with a new compression technique, we would have to create a new codec for that specific compression technique, and we could insert it somewhere in that tree of codecs that covered the entire data format.
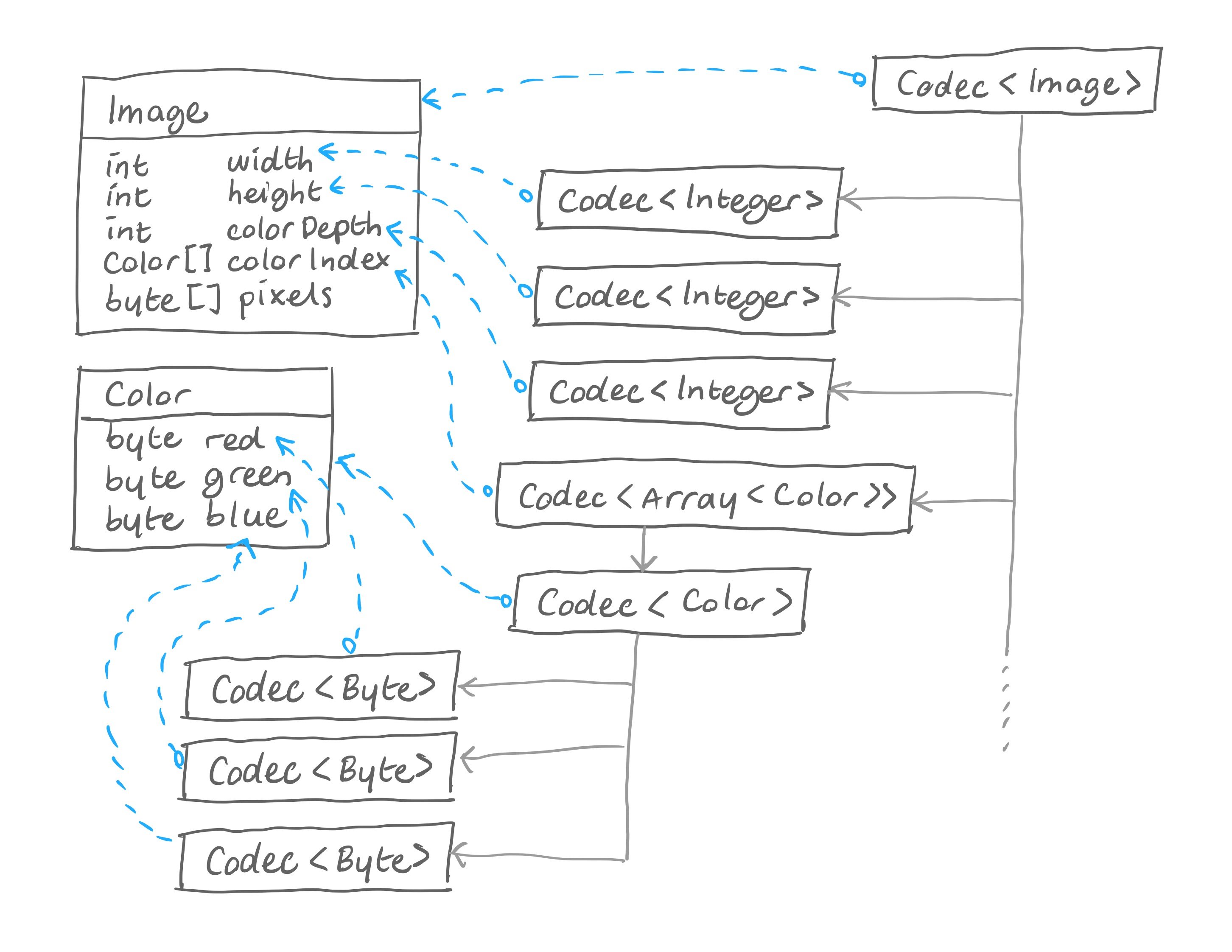
Each Codec consisted of four critical operations:
- A method to decode data from BitBuffer
- A method to encode data into a BitChannel
- A method to return the size of the data (in number of bits) as an Expression.
- A method to describe itself in HTML.
With the Codec defined as an interface, it would be possible to plug it in anywhere in our tree of Codecs. The remaining question was how we would build this tree of Codecs. Where would that tree itself be defined?
Since we were working on a Java codebase, I decided to keep the definition of that tree of Codecs inside the definition of the types we would encode into and decode from its bitstream-based representation, in Java annotations inside the source files of those types.
Since, in many cases, downstream Codecs of specific portions inside that tree had to be “configured” using data read upstream, I added an expression language that would allow you to express these configuration parameters in terms of the data available upstream.
This expression language also played a vital role in the generation of documentation. I aimed to have documentation that felt so natural, we could upload it to Wikipedia and have something sensible. For that reason, I defined the expression language so that it could be evaluated and rendered to human language.
How it played out
We were able to render the map from the data we decoded using our annotated Java data structure. Unfortunately, TomTom decided to kill it; they considered it a fruitless effort. From that point on, I kept working on it in my spare time and open sourcing it as Preon, first under the Apache Codehaus umbrella, later as a standalone project.
I kept refining the inner details until I landed on the abstractions that made sense. I then worked on the code to render sensible documentation from it, and tested it out on a couple of file formats in the wild, Java’s class file format being one of them. I created a Java representation of Java’s bytecode format, annotated it with the annotations that would create the codec, created a codec for it, and was able to parse Java .class files without any problem, and have readable documentation on Java’s bytecode format.
public class ClassFile {
@BoundBuffer(match = {
(byte) 0xca,
(byte) 0xfe,
(byte) 0xba,
(byte) 0xbe})
private byte[] magic;
@BoundNumber(size = "16", byteOrder = BigEndian)
private int minorVersion;
@BoundNumber(size = "16", byteOrder = BigEndian)
private int majorVersion;
@BoundNumber(size = "16", byteOrder = BigEndian)
private int constantPoolCount;
@BoundList(size = "constantPoolCount-1", types = {
ClassCpInfo.class,
DoubleCpInfo.class,
FieldRefCpInfo.class,
FloatCpInfo.class,
IntegerCpInfo.class,
InterfaceMethodRefCpInfo.class,
MethodRefCpInfo.class,
NameAndTypeCpInfo.class,
StringCpInfo.class,
Utf8CpInfo.class})
private CpInfo[] constantPool;The abstractions proved to be very useful. Based on the abstracts, I created a tool that relied on the definitions of these codecs to provide insight into hex dumps. Hovering over a hexdump would reveal the underlying data.
The ACM eventually published the results, and I presented the solution at OOPSLA in Orlando in 2009. Among my audience were Bjarne Stroustrup (C++), Guy Steele (Fortress, Java, Lisp), and other giants of our industry.
Preon has been used in Wifi hacking tools, in offshore cranes (for reasons beyond me), in in-flight infotainment systems, in telco, and I had people from the secret service attending my talks — so who knows where it ended up.